|
I'm a graduate student at the Technical University of Darmstadt - Visual Inference Lab, working with Prof. Stefan Roth under ELLIS. My broader research interest lies in the intersection of Computer Vision and Machine Learning. I was fortunate to be interned at FAIR at Meta AI during my graduate studies. My graduate study is generously supported by the ELIZA Scholarship from the German Academic Exchange Service (DAAD). Previously I spent a wonderful year at Meta AI as an AI Resident working on long-form video representation learning. I completed my bachlor's degree at University of Moratuwa, Sri Lanka, where my thesis was on Learning Representations for 3D Point Cloud Processing, advised by Dr. Ranga Rodrigo. I did a research internship with Prof. Salman Khan at MBZUAI, UAE during my undergraduate. I'm interested in broader areas in Computer Vision and Machine Learning with focus in the subdomains of Self-Supervised Learning, 3D Vision, and Learning with Limited Labels (few-shot, zero-shot). |

|
|
[Oct 2024] Joined FAIR at Meta as a Research Scientist Intern. |
|
I'm fascinated by the growth of computer vision community towards making the models see and understand the world as humans do. In particular, I'm intrigued by the results of the models learnt with self-supervision or with label constrained environments. |
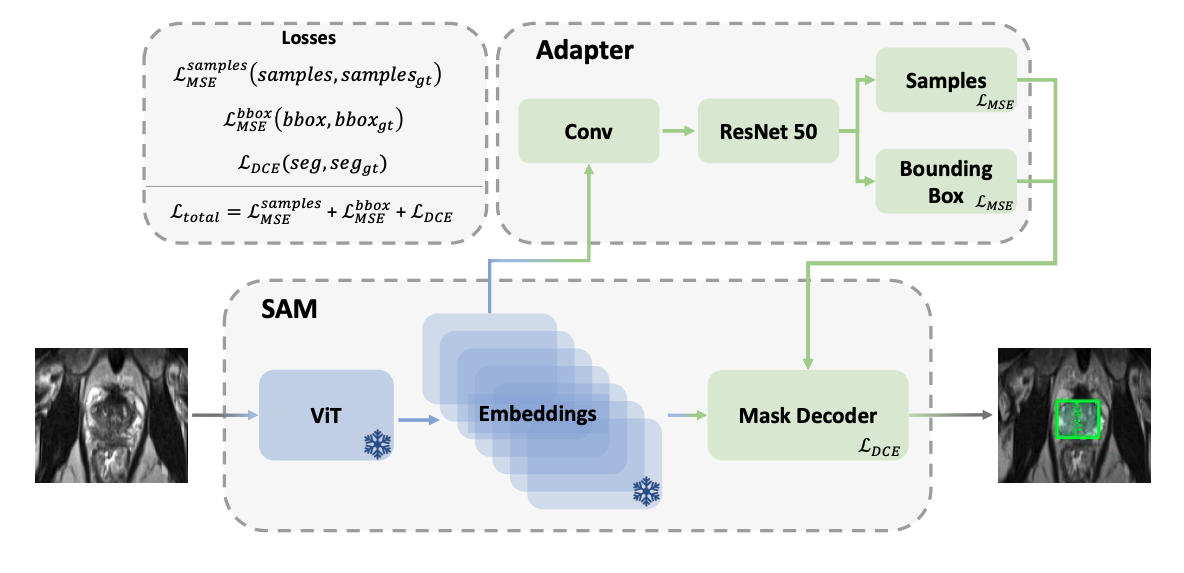
|
Amin Ranem, Mohamed Afham, Moritz Fuchs, Anirban Mukhopadhyay MIDL 2024 Paper / Code
|
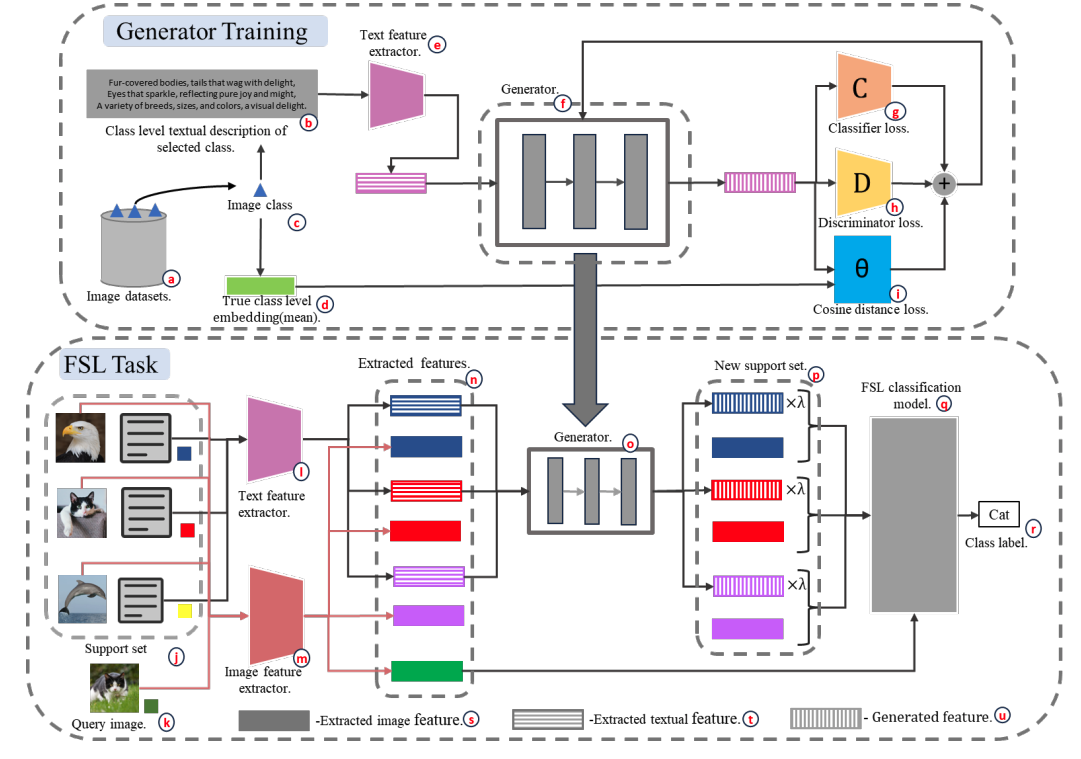
|
Heethanjan Kanagalingam, Thenukan Pathmanathan, Navaneethan Ketheeswaran, Mokeeshan Vathanakumar, Mohamed Afham, Ranga Rodrigo ACCV 2024 Paper / Code
|
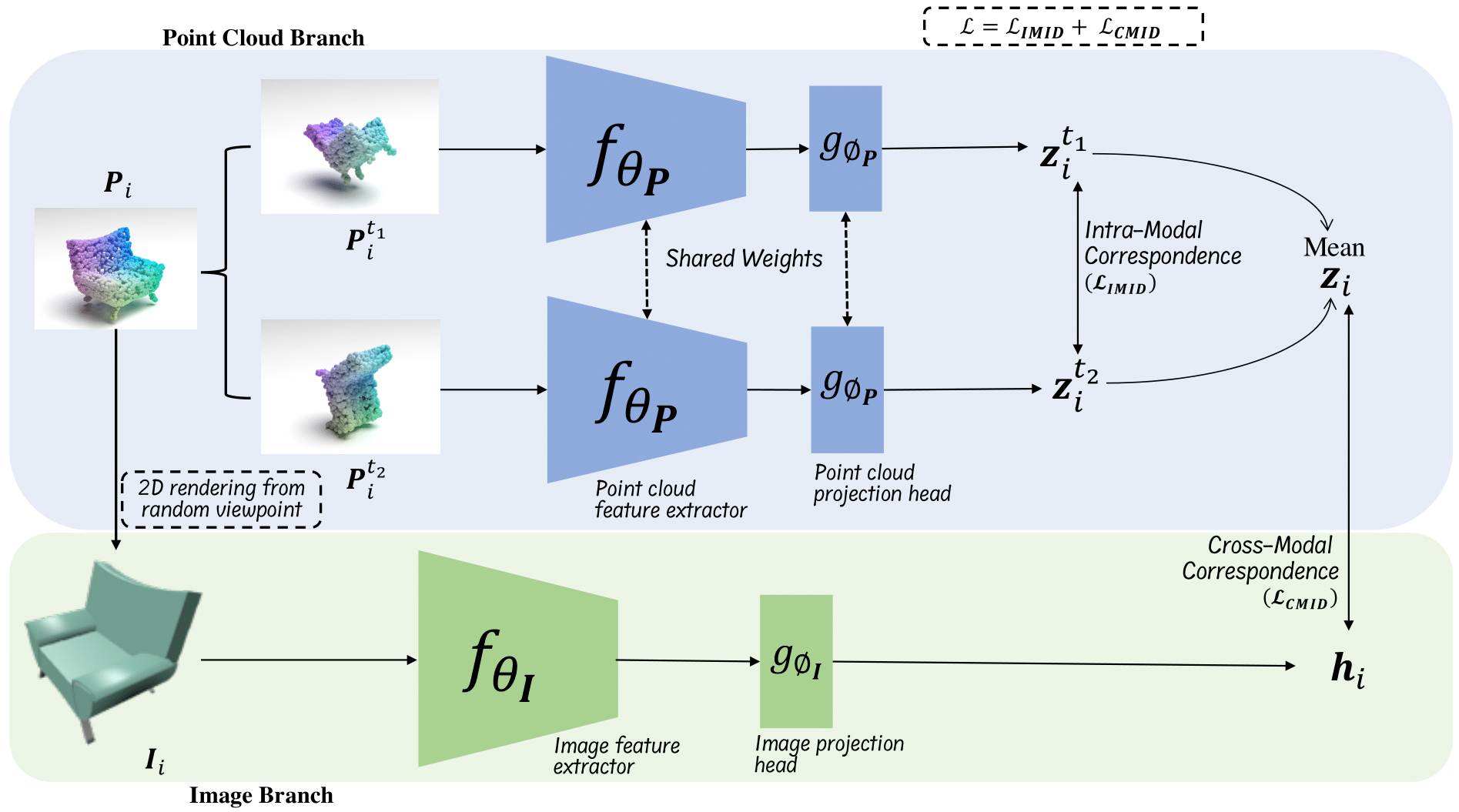
|
Mohamed Afham, Isuru Dissanayake, Dinithi Dissanayake, Amaya Dharmasiri, Kanchana Thilakarathna, Ranga Rodrigo CVPR 2022 Paper / Code / Project Page
|
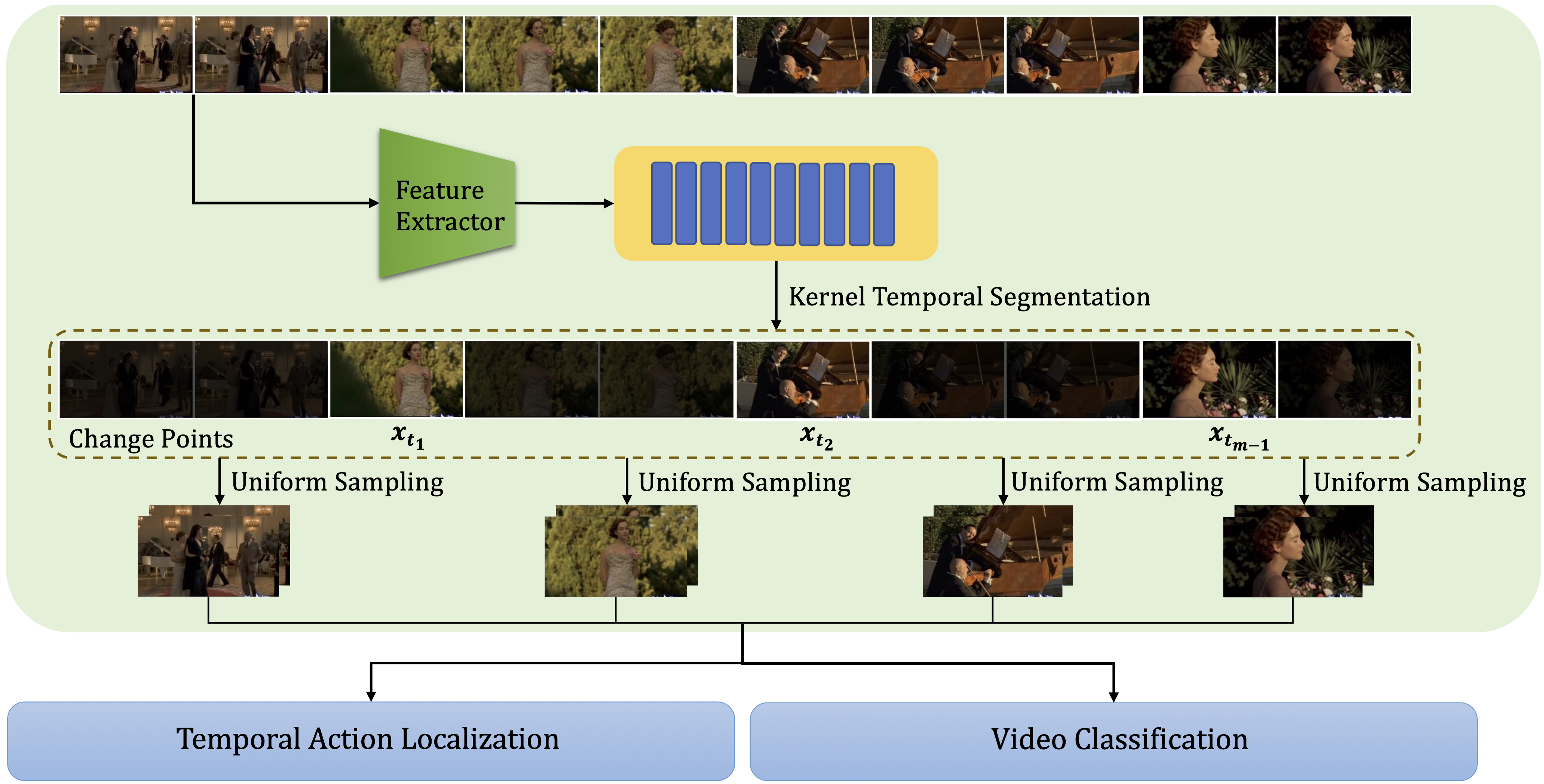
|
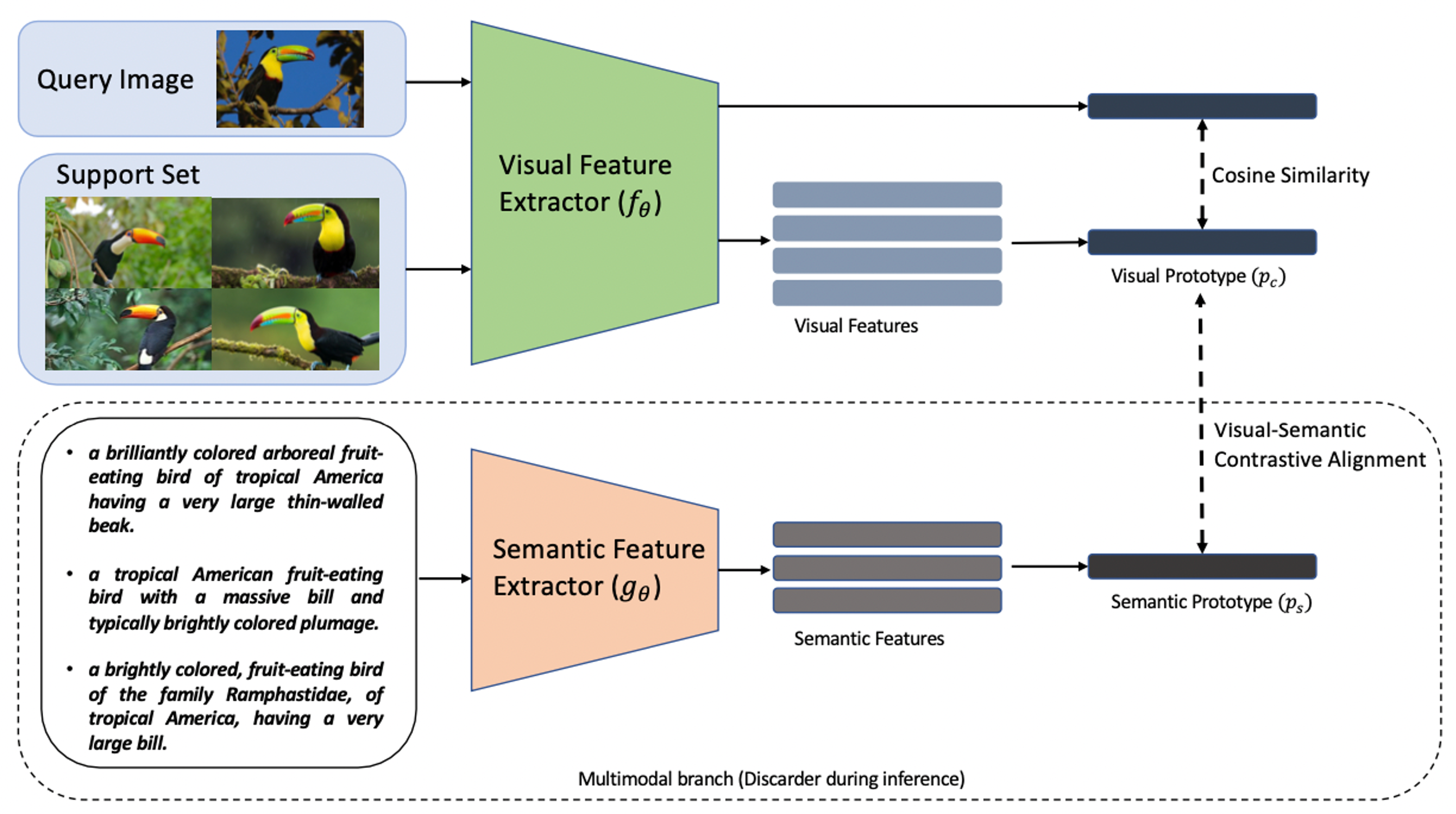
Mohamed Afham, Satya Narayan Shukla, Omid Poursaeed, Pengchuan Zhang, Ashish Shah, Sernam Lim ICCV 2023, Workshop on Resource Efficient Deep Learning for Computer Vision Paper
|
|
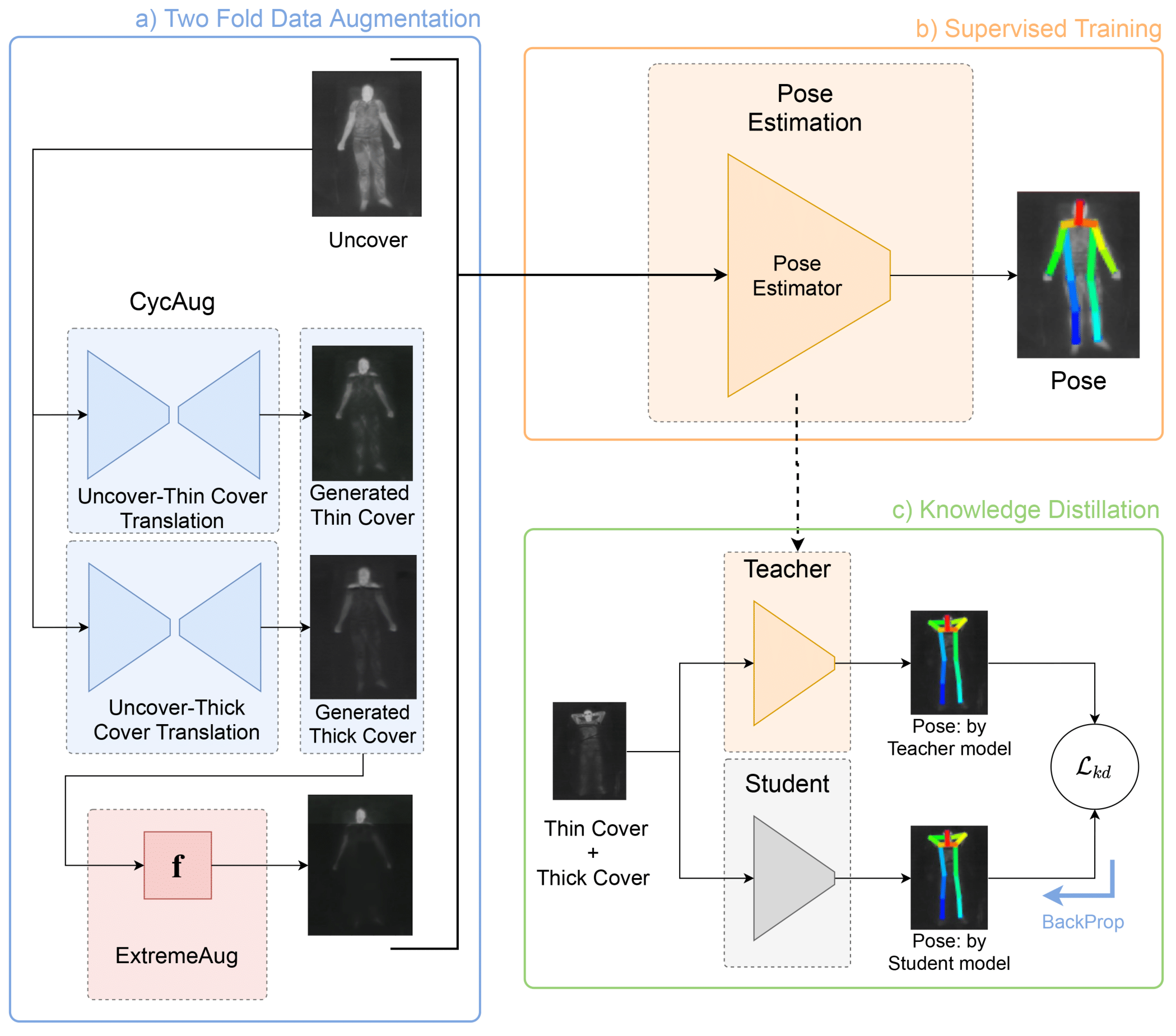
Mohamed Afham, Ranga Rodrigo ECCV 2022, Workshop on Computer Vision in the Wild Paper
|
|
Mohamed Afham*, Udith Haputhanthri*, Jathurshan Pradeepkumar*, Mithunjha Anandakumar, Ashwin De Silva, Chamira Edussooriya (* denotes equal contribution) ICASSP 2022 Paper / Code
|
|
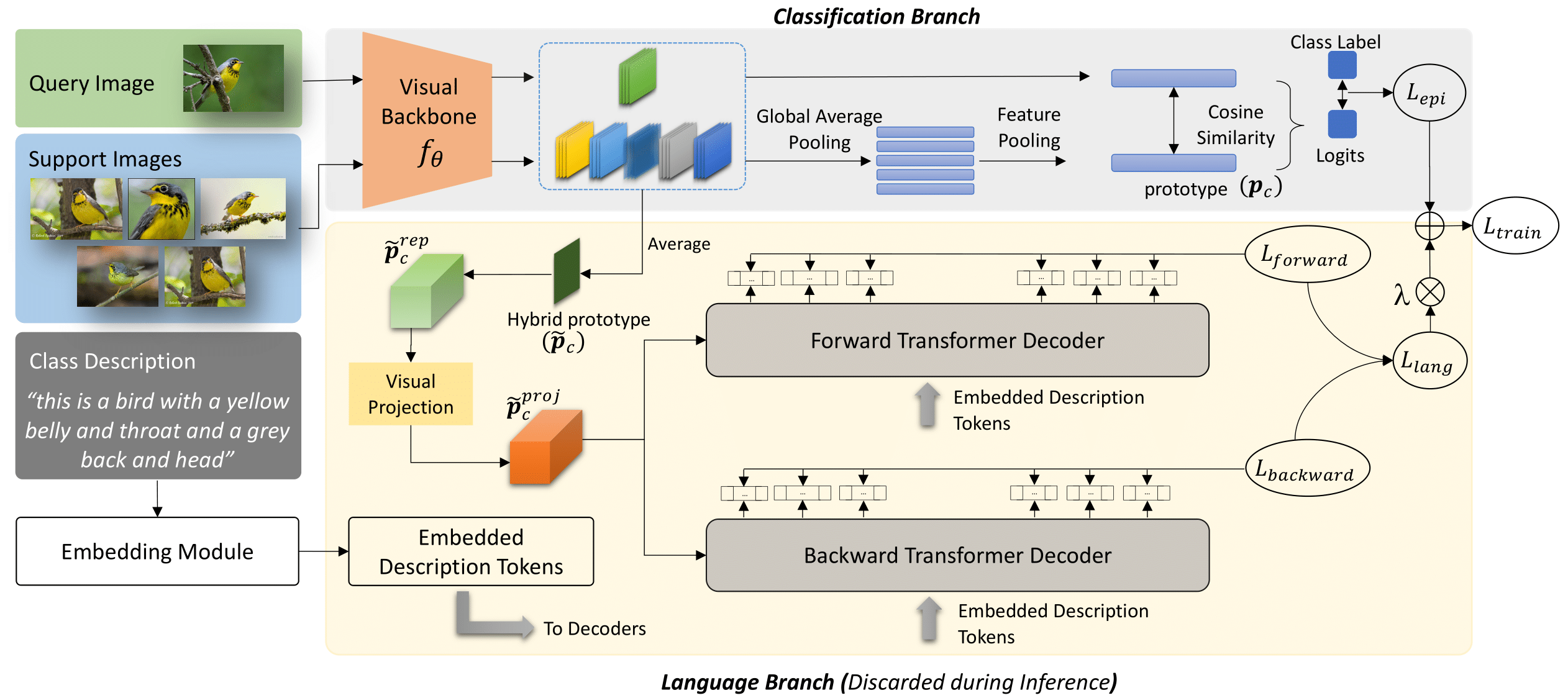
Mohamed Afham, Salman Khan, Muhammad Haris Khan, Muzammal Naseer, Fahad Shahbaz Khan BMVC 2021 Paper / Code / Presentation
|
|
|
|
|
Meta AI, Montreal, Canada Research Scientist Intern Oct 2024 – Mar 2025 |
|
|
Meta AI, New York, USA AI Resident Jul 2022 – Jul 2023 |
| VeracityAI, Colombo, Sri Lanka
Associate Machine Learning Engineer June 2021 - Feb 2022 | |||||||
| Mohamed Bin Zayed University of Artificial Intelligence, Abu Dhabi, UAE
Research Assistant Oct 2020 - Apr 2021 Advisor: Salman Khan | ||||||
|
|

| |||||||
| Technical University of Darmstadt, Germany
Master's + PhD in Computer Science Oct 2023 - Present | |||||||
| University of Moratuwa, Sri Lanka
Bachelor's in Science (Engineering) specialized in Electronics and Telecommunication Aug 2017 - Jul 2022 | |||||||||||||||||||
|
I borrowed this website layout from here! |